车机技术之基于ASR的麦克风阵列
概述
我们之前介绍过语音识别技术(ASR),随着ASR的逐步成熟,麦克风阵列也逐步得到重用。尤其在汽车里,空间有限,便于声音的近场定位,而麦克风的布线可以很方便和很规则,便于实现成阵列模式,不足的就是车辆运行过程中噪音比较大,当然其噪音还不算很复杂,加入CNN神经网络、深度学习等技术会有很好的除噪效果。
下面就麦克风阵列技术进行详述。

定义
麦克风阵列是指应用于语音处理的按一定规则排列的多个麦克风系统,也可以简单理解为2个以上麦克风组成的录音系统。
麦克风阵列一般来说有线形、环形和球形之分,严谨的应该说成一字、十字、平面、螺旋、球形及无规则阵列等。至于麦克风阵列的阵元数量,也就是麦克风数量,可以从2个到上千个不等。
早在20世纪70、80年代,麦克风阵列已经被应用于语音信号处理的研究中,进入90年代以来,基于麦克风阵列的语音信号处理算法逐渐成为一个新的研究热点。而到了21世纪的“声控时代”,这项技术的研究更是取得了长足进展。
在语音识别中的WER(词识别错误率)、SER(句子识别错误率),以及虚警率(错误触发语音识别)指标,都是麦克风阵列在实现时需要一起考虑的问题。

作用及关键技术
语音增强
语音增强是指当语音信号被各种各样的噪声(包括语音)干扰甚至淹没后,从含噪声的语音信号中提取出纯净语音的过程。
从20世纪60年代开始,Boll等研究者先后提出了针对使用一个麦克风的语音增强技术,称为单通道语音增强。因为它使用的麦克风个数最少,并且充分考虑到了语音谱和噪声谱的特性,使得这些方法在某些场景下也具有较好的噪声抑制效果,并因其方法简单、易于实现的特点广泛应用于现有语音通信系统与消费电子系统中。但是,在复杂的声学环境下,噪声总是来自于四面八方,且其与语音信号在时间和频谱上常常是相互交叠的,再加上回波和混响的影响,利用单麦克风捕捉相对纯净的语音是非常困难的。而麦克风阵列融合了语音信号的空时信息,可以同时提取声源并抑制噪声。目前基于线性阵列、平面阵列、空间立体阵列的波束形成和降噪技术,加上神经网络、深度学习在各种实际环境中的样本训练,实现噪声抑制、混响去除、人声干扰抑制、声源测向、声源跟踪、阵列增益等功能。
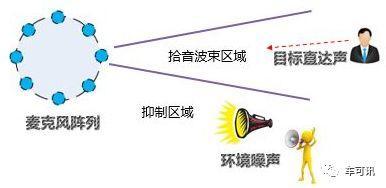
声源定位和测向
现实中,声源的位置是不断变化的,这对于麦克风收音来说,是个障碍。麦克风阵列则可以进行声源定位,声源定位技术是指使用麦克风阵列来计算目标说话人的角度和距离,从而实现对目标说话人的跟踪以及后续的语音定向拾取,是人机交互、音视频会议等领域非常重要的前处理技术。
声源测向可以基于能量方法,也可以基于谱估计,阵列也常用TDOA(利用各麦克风对于声源的到达时差)技术。声源测向一般在语音唤醒阶段实现,VAD(语音活性检测)技术其实就可以包含到这个范畴,也是未来功耗降低的关键研究内容。
当然对于汽车来说,各座位固定,人也不能到处移动,所以声源定位比较简单。
噪声抑制
语音识别倒不需要完全去除噪声,相对来说通话系统中需要的技术则是噪声去除。这里说的噪声一般指环境噪声,比如空调噪声,发动机噪声,轮胎噪声,风噪等,这类噪声通常不具有空间指向性,传入车内之后的能量虽然比较大,但还不会掩盖正常的语音,只是影响了语音的清晰度和可懂度。
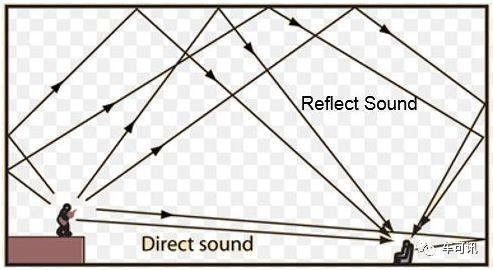
混响消除
混响去除的效果很大程度影响了语音识别的效果。当声源停止发声后,声波在房间内要经过多次反射和吸收,似乎若干个声波混合持续一段时间,这种现象叫做混响。混响会严重影响语音信号处理,比如互相关函数或者波束主瓣,降低测向精度。
利用麦克风阵列去混响的主要方法有以下几种:
(1)基于盲语音增强的方法,即将混响信号作为普通的加性噪声信号,在这个上面应用语音增强算法。
(2)基于波束形成的方法,通过将多麦克风对收集的信号进行加权相加,在目标信号的方向形成一个拾音波束,同时衰减来自其他方向的反射声。
(3)基于逆滤波的方法,通过麦克风阵列估计房间的房间冲击响应,设计重构滤波器来补偿来消除混响。
对于汽车来说,车内吸音材料很多,一般混响问题倒不是特别大。
声源信号提取或分离
声源信号的提取就是从多个声音信号中提取出目标信号,声源信号分离技术则是将需要将多个混合声音全部提取出来。
利用麦克风阵列做信号的提取和分离主要有以下几种方式:
(1)基于波束形成的方法,即通过向不同方向的声源分别形成拾音波束,并且抑制其他方向的声音,来进行语音提取或分离;
(2)基于传统的盲源信号分离的方法进行,主要包括主成分分析和基于独立成分分析的方法。
回声抵消
严格来说,这里不应该叫回声,应该叫“自噪声”。回声是混响的延伸概念,这两者的区别就是回声的时延更长。一般来说,超过100毫秒时延的混响,人类能够明显区分出,似乎一个声音同时出现了两次,我们就叫做回声。实际上,这里所指的是语音交互设备自己发出的声音,比如Echo音箱,当播放歌曲的时候若叫Alexa,这时候麦克风阵列实际上采集了正在播放的音乐和用户所叫的Alexa声音,显然语音识别无法识别这两类声音。回声抵消就是要去掉其中的音乐信息而只保留用户的人声,之所以叫回声抵消,只是延续大家的习惯而已,其实是不恰当的,在通信的电话机行业,这个叫消侧音。
波束形成
波束形成是通用的信号处理方法,这里是指将一定几何结构排列的麦克风阵列的各麦克风输出信号经过处理(例如加权、时延、求和等)形成空间指向性的方法。波束形成主要是抑制主瓣以外的声音干扰。
模型匹配
主要是和语音识别以及语义理解进行匹配,语音交互是一个完整的信号链,从麦克风阵列开始的语音流不可能割裂的存在,必然需要模型匹配在一起。实际上,效果较好的语音交互专用麦克风阵列,通常是两套算法,一套内嵌于硬件实时处理,另外一套是基于该硬件的匹配语音软件处理,还有基于云端的语音识别的深度学习处理。
原理
因为汽车的拾音距离都比较近,适合使用近场模型。如下图所示是一个简单的基于均匀线阵的近场模型,声波在传播过程中要发生幅度衰减,衰减因子与传播距离成正比。近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元接收信号的幅度差别。下图中,q为麦克风阵元的个数,r为声源到阵列中心(参考点)的距离,α为声源与阵元连线之间的夹角,rn为声源到阵元n的距离,dn为阵元n到参考点的距离,Δd为相邻阵元间距。
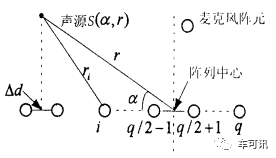
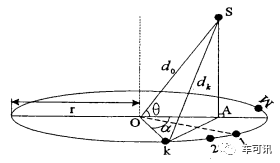
下图为均匀圆阵的近场模型,多个麦克风均匀地排列在一个圆周上,就构成了一个麦克风均匀圆阵列 (UCA)。以UCA中心(圆心O)作为参考点,d0 表示信源S与阵列中心的距离,A为信源到UCA平面的垂足,以OA连线所在的半径为参考线,号麦克风所在半径与OA夹角为Δφθ,表示信号到达方向(SO与参考线的夹角),di(i = 1 ,2 , …, M)表示信源到第个麦克风的距离。
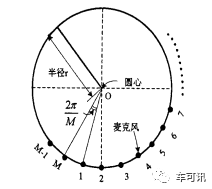
UCA任意两个相邻麦克风对应的圆周角为2π/ M,M为麦克风的个数,如下图所示:
当信源离麦克风阵列较近时,大家熟知的基于平面波前的远场模型不再适用,必须采用更为精确也更为复杂的基于球面波前的近场模型。声波在传播过程中要发生幅度衰减,其幅度衰减因子与传播距离成正比。信源到麦克风阵列各阵元的距离是不同的,因此声波波前到达各阵元时,幅度也是不同的。近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元因接收信号幅度衰减的不同所带来的影响。对于远场模型,信源到各阵元的距离差与整个传播距离相比非常小,可忽略不计;对于近场模型,信源到各阵元的距离差与整个传播距离相比较大,必须考虑各阵元接收信号的幅度差。
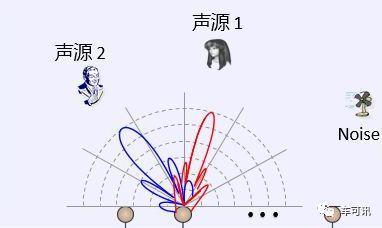
具体的算法既要考虑到麦克风阵列各阵元接收信号的相位差,又得考虑到各阵元接收信号的幅度差,从而实现对声源的二维(或三维)定位。根据声源的方位信息,可以使用波束形成技术获得形成一个或多个波束指向感兴趣的声源,从而更好地去噪,完成对该声源信号的提取和分离。由于可以利用的方位信息是二维的,因此,相应的波束具有二维特性。即除了对某一方向的信号有增强作用外,还能对同一方向、不同距离的信号有选择作用,这对于背景噪声和回声消除是非常有用的。
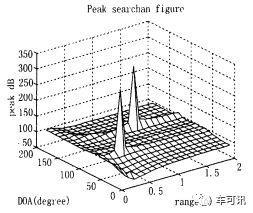
下图为一个实际算法的仿真结果,可以看到,声源相对于参考点,它的角度和距离都相当清晰可辨:
趋势
声学的非线性处理研究:现在的算法基本忽略了非线性效应,所以当前麦克风阵列的基本原理和模型方面就存在较大的局限,今后在非线性处理方面会有比较深入的研究。
麦克风阵列的小型化:现今的麦克风阵列受制于半波长理论的限制,现在的口径还是较大,借鉴雷达领域的合成孔径方法,麦克风阵列可以做的更小。
麦克风阵列的低成本化:随着近年来新技术的应用,多麦克风阵列的成本下降将会非常明显。
多人声的处理和识别:现在的麦克风阵列和语音识别还都是单人识别模式,对于人耳的鸡尾酒会效应(人耳可以在嘈杂的环境中分辨想要的声音,并且能够同时识别多人说话的声音),随着深度学习的研究深入和应用普及,这方面应该会有较大突破。
现状
当前成熟的麦克风阵列的主要包括:讯飞的2麦、4麦和6麦方案,思必驰的6+1麦方案,云知声(科胜讯)的2麦方案,以及声智科技的单麦、2麦阵列、4(+1)麦阵列、6(+1)麦阵列和8(+1)麦阵列方案,其他家也有麦克风阵列的硬件方案,但是缺乏前端算法和云端识别的优化。由于各家算法原理的不同,有些阵列方案可以由用户自主选用中间的麦克风,这样更利于用户进行ID设计。其中,2个以上的麦克风阵列又分为线形和环形两种主流结构,而2麦的阵列则又有同边和前后两种结构。
从汽车的整体结构来看,选用多麦是可行和必须的,至少6麦以上为好,每个前后每个座位处可以各放置1个,前端中控上可以放置1至2个(司机可多1个,另一个可以单独用来指向性收集噪声用来消噪),中部的扶手置物盒处可以放置1个,这样下来定位、消噪、消回声都能比较好的解决。
结论
总之,语音操作时代已经来临,尤其在于车机方面,已经要成为标配了,但是由于各个应用和底层系统之间的接口问题,比如采用的基础语音识别厂家不一、各个应用的语音命令可能冲突或不支持语音、进而车机整体层面语音命令混乱,从而导致语音操作还不具有统一标准,在实际使用中问题层出不穷。
这个问题可能需要等到各大原车厂意识到之后,统一指定语音识别的底层基础厂商,统一指定上层应用厂商的语音命令,进一步的统一控制和调度各个应用的语音命令之后才可能带来体验很好的语音操作。后装市场还没有哪家有实力和号召力实现这三个统一,所以目前国内还看不到很好用的语音操作车机。