Hadoop性能模型(6)
第三步:磁盘和内存中的文件全部合并。

排序阶段的消耗是:

3.3 Reduce和Write阶段模型
最终,用户定义的reduce函数被执行,输出结果写入HDFS。

reduce函数的输入依靠内存和磁盘上的shuffle文件(在shuffle和Sort阶段生成)。
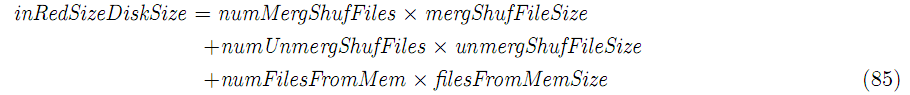
整个Write阶段的消耗:

3.4 整个Reduce任务模型
上面的模型是单个reduce任务,整个单个reduce任务的消耗:
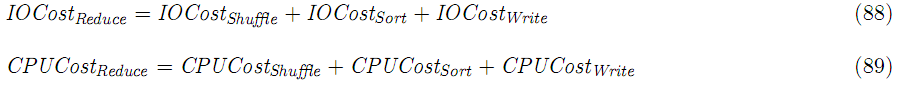
人工智能 云计算 大数据 物联网 IT 通信 嵌入式
第三步:磁盘和内存中的文件全部合并。
排序阶段的消耗是:
3.3 Reduce和Write阶段模型
最终,用户定义的reduce函数被执行,输出结果写入HDFS。
reduce函数的输入依靠内存和磁盘上的shuffle文件(在shuffle和Sort阶段生成)。
整个Write阶段的消耗:
3.4 整个Reduce任务模型
上面的模型是单个reduce任务,整个单个reduce任务的消耗: