Hadoop性能模型(4)
3 Reduce任务阶段性能模型
Reduce任务分为四个阶段:
1. Shuffle: 从map节点拷贝map输出到reduce节点,需要的话解压缩,该阶段可能会有部分merge。
2. Merge:从不同的mappers合并排序的分片,形成reduce函数的输入。
3. Reduce:执行用户提供的reduce函数。
4. Write:写输出到HDFS,需要的话压缩。
3.1 Shuffle阶段模型
下面的讨论基于单个reduce任务,在shuffle阶段,框架从每个mapper取得map输出分片,拷贝到reduce节点。假如map输出被压缩,则需要解压,每个map分片到达reduce:
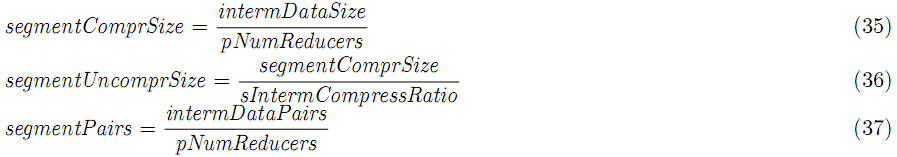
这里的intermDataSize和intermDataPairs是单个mapper的中间输出的数据大小和k-v对数。
单个reduce取得的数据:
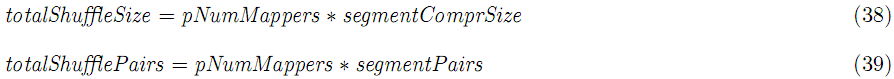
数据拷贝到reduce后,放在shuffle buffer内存的大小:
![]()
当内存大小达到门限,或分片数大于pInMemMergeThr,这些分片被合并,随即spill到磁盘,建立新的spill文件(文件名为shuffleFile),合并门限:
![]()
然而,当分片大小大于shuffleBufferSize的25%,这个分片将直接写入磁盘,而不需要经过内存(进一步,没有内存合并阶段)。

一个shuffle文件合并numSegInShuffleFile个分片,如果有combine功能,在合并期间使用,注意,假如numSegInShuffleFile大于numMappers,则不用合并。

在合并的最后,一些分片也许留在内存:

当shuffle文件数量超过一定门限(2XpSortFactor-1),一个新的合并线程会被触发,pSortFactor个shuffle文件会被合并成一个更大的排序文件。在磁盘合并期间combine功能不使用。这样子的merge总数是:
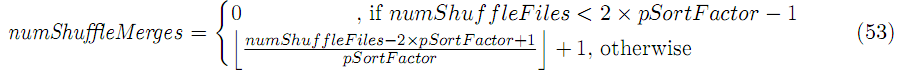
在shuffle阶段末尾,合并和非合并的shuffle文件都将保存于磁盘:
