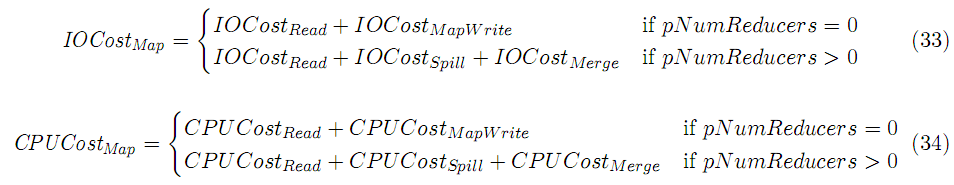Hadoop性能模型(3)
2.3 Merge阶段模型
merge阶段的目标是合并所有spill文件到一个单一的输出文件,写入本地磁盘。多于一个spill文件的时候就会发生merge,也许会有多次merge,取决于pSortFactor参数。定义一次merge最多合并pSortFactor决定的spill文件数。定义一轮merge为一次或多次merge,在spill阶段再产生spill文件或前一轮spill再产生spill文件的话就会有多轮merge出现。例如,假定numSpills=30、pSortFactor=10,因此3个merge会执行,建立三个新文件,这是第一轮,接着,三个新文件将merge到一起,这是第二轮,也是最后一轮。
如果最后一次需要合并的spill数量大于等于pNumSpillsForComb,combiner需要再次使用。进一步,我们把中间merge和最后merge分开。中间merge,我们计算单个spill将被读多少次。
接下来的部分假定numSpills<=pSortFactor,这种情况下,为了计算在中间merge阶段spills数量,我们使用仿真方法。
第一次merge是统一的,因为hadoop会计算优化spill文件数用来合并,以便所有merge都刚好是pSortFactor个文件。
既然Reduce也会包含一个类似的Merge阶段,定义三个公式,之后可以重用:
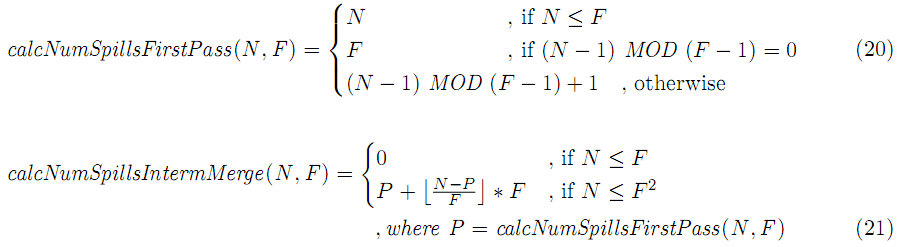
第一次merge期间spill文件数:
![]()
中间merge期间spill文件数:
![]()
merge总数:
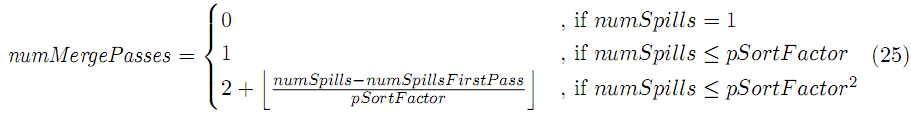
最后一轮merge的spill文件数(第一次+中间+余下的spill文件):
![]()
总的spill过的记录数:
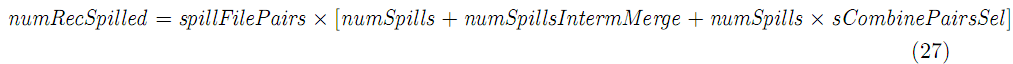
最终map输出大小和k-v对数:

该阶段的消耗:

2.4 整个map阶段模型