Hadoop性能模型(2)
2. MAP阶段性能模型
前面说过,map任务执行分为五个阶段:
1. Read:读入split,建立key-value对。
2. Map:执行用户提供的map函数。
3. Collect:收集map输出到buffer或分区。
4. Spill:排序,需要的话combine,需要的话压缩,最后spill到磁盘,建立spills文件。
5. Merge:合并spills文件到一个单个文件,合并也许执行多轮。
2.1 Read和Map阶段模型
这个阶段读入split,需要的话解压缩,建立key-value对,把输入传给用户定义的map函数。
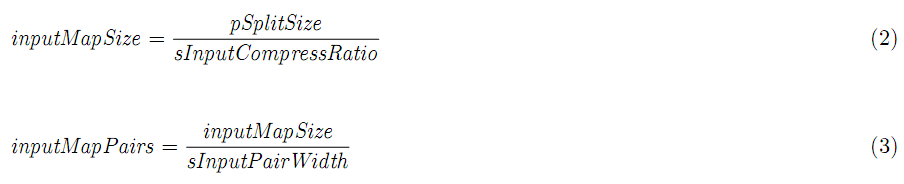
该阶段的消耗:
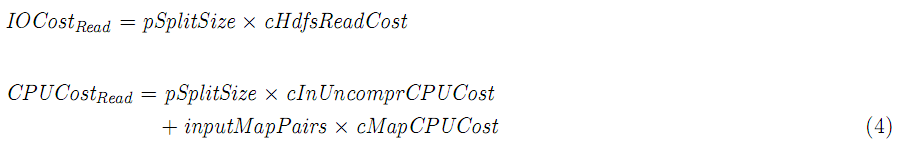
假如MR job只有mapper(例如:pNumReduces=0),spill和合并阶段不用执行,map输出将直接写到HDFS。

2.2 Collect和Spill阶段模型
map函数产生的key-value对存放在map的内存中,公式化map输出:
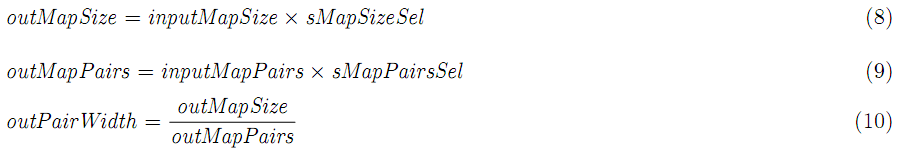
内存buffer分为两部分:保存key-value对的序列化部分,和存储每对meta数据的计数部分。当这两部分被填满的时候(基于pSpillPerc门限值),这些key-value对被分区、排序、spill到磁盘,序列化buffer的最大key-value对数是:
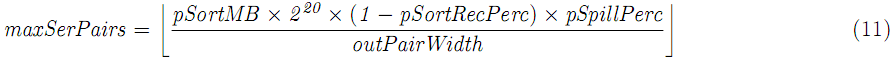
计数buffer的最大key-value对数是:
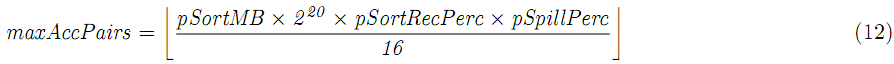
spill之前的key-value对数和buffer大小的关系是:
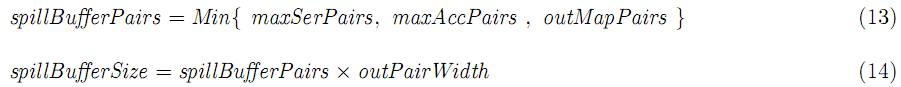
整个spill的数量是:

这个key-value对数和每个spill的大小取决于每个k-v对的宽度,combine函数的使用以及中间数据压缩的使用。缺省sIntermCompressRatio设置为1,意思是中间结果不压缩,缺省sCombinePairsSel设置为1,意思是没有combine函数使用。
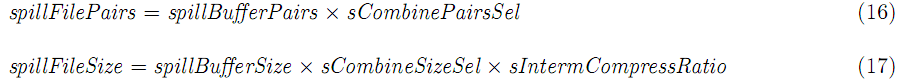
本阶段的消耗:
